Open-WebUI介绍
Open WebUI 是一种基于 Web 的用户界面,用于管理和操作各种本地和云端的人工智能模型。它提供了一个直观的图形化界面,使用户可以方便地加载、配置、运行和监控各种 AI 模型,而无需编写代码或使用命令行界面。
优点
Open-WebUI 是一款功能强大且易于使用的 Web 界面,可让您轻松与大型语言模型 (LLM) 进行交互。它具有以下优点:
用户界面
直观且响应式,可在任何设备上提供卓越的体验。
支持多种主题和自定义选项,以满足您的个人喜好。
性能
快速响应和流畅的性能,即使在处理复杂任务时也是如此。
支持多模型和多模态交互,可实现更强大的功能。
功能
- 全面的 Markdown 和 LaTeX 支持,可轻松格式化和共享文本。
- 本地 RAG 集成,可通过文档检索增强 LLM 功能。
- Web 浏览功能,可直接从聊天中访问和交互网站。
- 提示预设,可快速启动常见对话。
- RLHF 注释,可通过提供反馈来帮助改进 LLM。
- 对话标记,可轻松组织和查找对话。
- 模型管理功能,可轻松添加、删除和更新模型。
- 语音输入和文本转语音,可实现自然语言交互。
- 高级参数微调,可根据您的需要定制 LLM 行为。
- 图像生成集成,可创建令人惊叹的视觉内容。
API
支持 OpenAI API 和其他兼容 API,可扩展 LLM 功能。
提供 API 密钥生成和外部 Ollama 服务器连接等高级功能。
安全性
基于角色的访问控制 (RBAC),可确保仅授权用户才能访问敏感信息。
模型白名单和受信任的电子邮件身份验证可增强安全性。
后端反向代理支持可保护您的 Ollama 实例。
其他
支持多种语言,可满足全球用户的需求。
定期更新和新功能,确保您始终拥有最佳体验。
部署教程
1.打开官网地址
打开,开源项目Open-WebUI地址放在下方
点击!https://github.com/open-webui/open-webui
点进去之后里边也是有相应的功能介绍,以及不同环境下的安装(具体看文档介绍)
2.安装Docker
自行去官网安装,安装教程也是十分的简单
3.Open WebUI下载
安装完成之后重启电脑,打开Docker
复制这条命令( Ollama 在您的计算机上使用以下命令)
不同的条件下,有不同的命令,详细见开源地址所述
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main参数详解
docker run: 启动一个新的 Docker 容器。-d: 以守护进程模式运行容器,容器将在后台运行。-p 3000:8080: 将本地机器的端口 3000 映射到容器内的端口 8080。这意味着你可以通过访问http://localhost:3000来访问运行在容器内的服务。--add-host=host.docker.internal:host-gateway: 将主机名host.docker.internal映射到 Docker 网关。这对于在容器内访问主机服务很有用。-v open-webui:/app/backend/data: 将本地的open-webui卷映射到容器内的/app/backend/data目录。这用于持久化数据,确保即使容器停止或重新启动,数据也不会丢失。--name open-webui: 为容器指定一个名称open-webui,以便于管理和识别。--restart always: 设置容器的重启策略为always,这意味着容器如果停止(例如由于崩溃或系统重启),Docker 会自动重启它。ghcr.io/open-webui/open-webui:main: 使用来自 GitHub 容器注册表(GitHub Container Registry)的open-webui镜像,并指定使用main标签的版本。
复制完成之后打开我们的cmd命令行
复制copy的命令一键运行即可
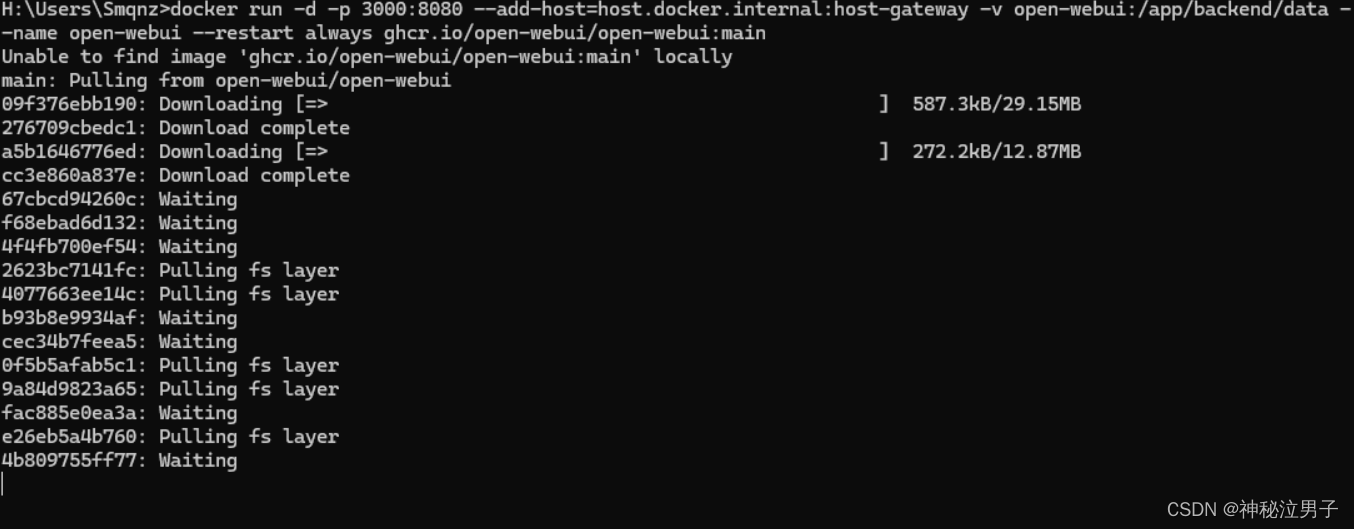
等待下载完成即可
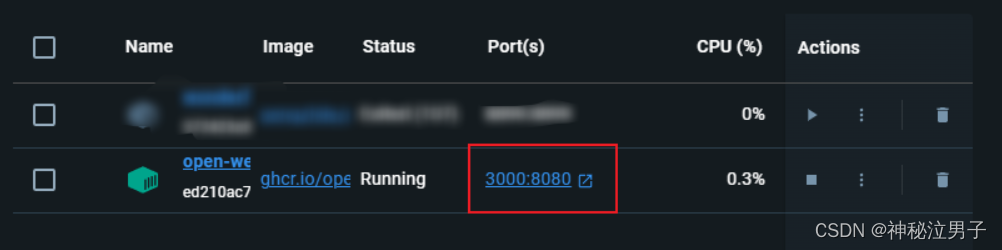
安装完成之后访问本地的3000端口
也可以点击自己的Docker,点击访问即可
首次登录需要创建用户
注册一个用户
成功的登录到UI界面
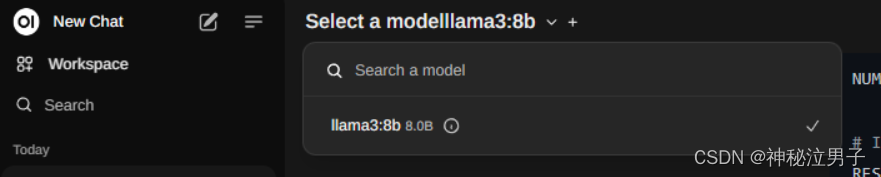
成功的进入之后,我们选择相应的模型,因为我本地下载过8B的模型,所以它自动会识别的。
选择好模型之后,我们来对他进行提问
可以看出类似于ChatGPT的聊天框十分的便捷
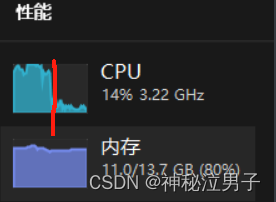
但是在访问的时候占用的是本地的内存和CPU,大家可以明显的看出 CPU飙升(我个人的笔记本性能没有那么好,并且是集成显卡)。
回答的速度是根据自己电脑的性能挂钩,并且选择的模型,也可以选择自己适合的模型
可以看出回答的也是十分的详细

功能介绍
1.AI编程
测试以下编程能力
问题:用shell脚本编写一个ping通网段所有主机 要求如果可以访问返回YES,否则就NO
它的回答:
下面是一个 shell 脚本,用于检查指定网络范围内的所有主机是否可访问,并相应地返回“YES”或“NO”:ping
#!/bin/bash
# Set the network range (e.g. 192.168.1.0/24)
NETWORK_RANGE="192.168.1.0/24"
# Set the number of hosts to ping (e.g. 254 for a /24 subnet)
NUM_HOSTS=$(ipcalc -n $NETWORK_RANGE | awk '{print $2}' | grep -oE '[0-9]+$')
# Initialize the result
RESULT="NO"
# Ping each host in the network range
for i in $(seq 1 $NUM_HOSTS); do
HOST=$NETWORK_RANGE".$i
if ping -c 1 -W 1 $HOST &> /dev/null; then
RESULT="YES"
break
fi
done
echo "$RESULT"让我解释一下脚本的工作原理:
- 我们使用(一种计算 IP 地址范围的工具)设置要 ping 的网络范围和主机数量。例如,如果我们要检查子网中的所有主机,我们将设置 和 。ipcalc“192.168.1.0/24“NETWORK_RANGE=”192.168.1.0/24″“NUM_HOSTS=Extra close brace or missing open brace‘)
- 我们将结果初始化为“NO”(假设并非所有主机都可以访问)。
- 我们使用循环和命令遍历网络范围内的每个主机,该命令生成从 1 到 的数字序列。对于每个主机,我们通过将网络范围与主机编号(例如,等)连接起来构建完整的IP地址。
for``seq``$NUM_HOSTS``192.168.1.1``192.168.1.2 - 我们用来检查主机是否可访问。如果是,我们将结果更新为“YES”并打破循环。
ping - 最后,我们打印结果。
您可以将此脚本保存到文件(例如 )中,并使用 .然后,您可以通过在终端中执行来运行它。ping_network.sh``chmod +x ping_network.sh``./ping_network.sh
注意:此脚本假定您已安装在系统上。如果没有,您可以使用包管理器安装它(例如,在基于 Ubuntu 的系统上)。此外,如果网络范围较大或主机响应缓慢,则此脚本可能需要一段时间才能运行。您可以修改脚本以使用,或者如果需要加快该过程。ipcalc``apt-get install ipcalc``parallel processing``concurrent ping
可以看的出来回答的也是十分的详细
可以看出回答的十分的仔细,不仅写出了脚本,而且还对于代码进行解释,我仅仅采用的是8B的模型,还有更高的模型。
2.聊天历史
当我们退出网页之后,重新登录,发现聊天记录仍然是在的,十分的便捷
就像官网所说的那样
- 再生历史访问:轻松重温和探索您的整个再生历史。
- 聊天记录:轻松访问和管理您的对话记录。
- 存档聊天:毫不费力地存储与 LLM 的完整对话以供将来参考,保持整洁整洁的聊天界面,同时允许轻松检索和参考。
3.自定义Web的界面
管理链接更新模型

多的就不在介绍,大家部署完成之后自行实践,设置的项十分的重要。
同时还支持很多功能,自定义模型
上传下载好的模型文件
GGUF 文件模型创建:通过直接从 Web UI 上传 GGUF 文件,轻松创建 Ollama 模型。简化流程,提供从机器上传或从 Hugging Face 下载 GGUF 文件的选项。
同时还支持图像生成集成,OpenAI API集成,外部Ollama服务器链接,多用户管理,等等… 感兴趣的话可以去开源项目的文档去详细的了解,对你十分的有帮助